Federated Learning คืออะไร? และทำไมโรงงานถึงต้องรู้?
หนึ่งในความท้าทายที่ใหญ่ที่สุดในการนำ AI มาใช้ในโรงงานอุตสาหกรรมคือ “ไม่อยากส่งข้อมูลออกนอกโรงงาน” — ไม่ว่าจะเป็นข้อมูลการผลิต, สูตรการผลิต, พารามิเตอร์เครื่องจักร, หรือข้อมูลลูกค้า ล้วนเป็นความลับทางการค้า (Trade Secret) ที่ไม่ควรส่งไปยัง Cloud ของผู้ให้บริการ AI
Federated Learning (FL) คือเทคนิค Machine Learning ที่อนุญาตให้ ฝึกโมเดล AI โดยไม่ต้องย้ายข้อมูลออกจากแหล่งกำเนิด — โรงงานแต่ละแห่งฝึกโมเดลจากข้อมูลของตัวเอง แล้วส่งเฉพาะ “น้ำหนักของโมเดล” (Model Weights/Gradients) ไปรวมกันที่ Central Server ทำให้ได้โมเดลที่แม่นยำกว่า โดยข้อมูลดิบไม่เคยออกจากโรงงาน
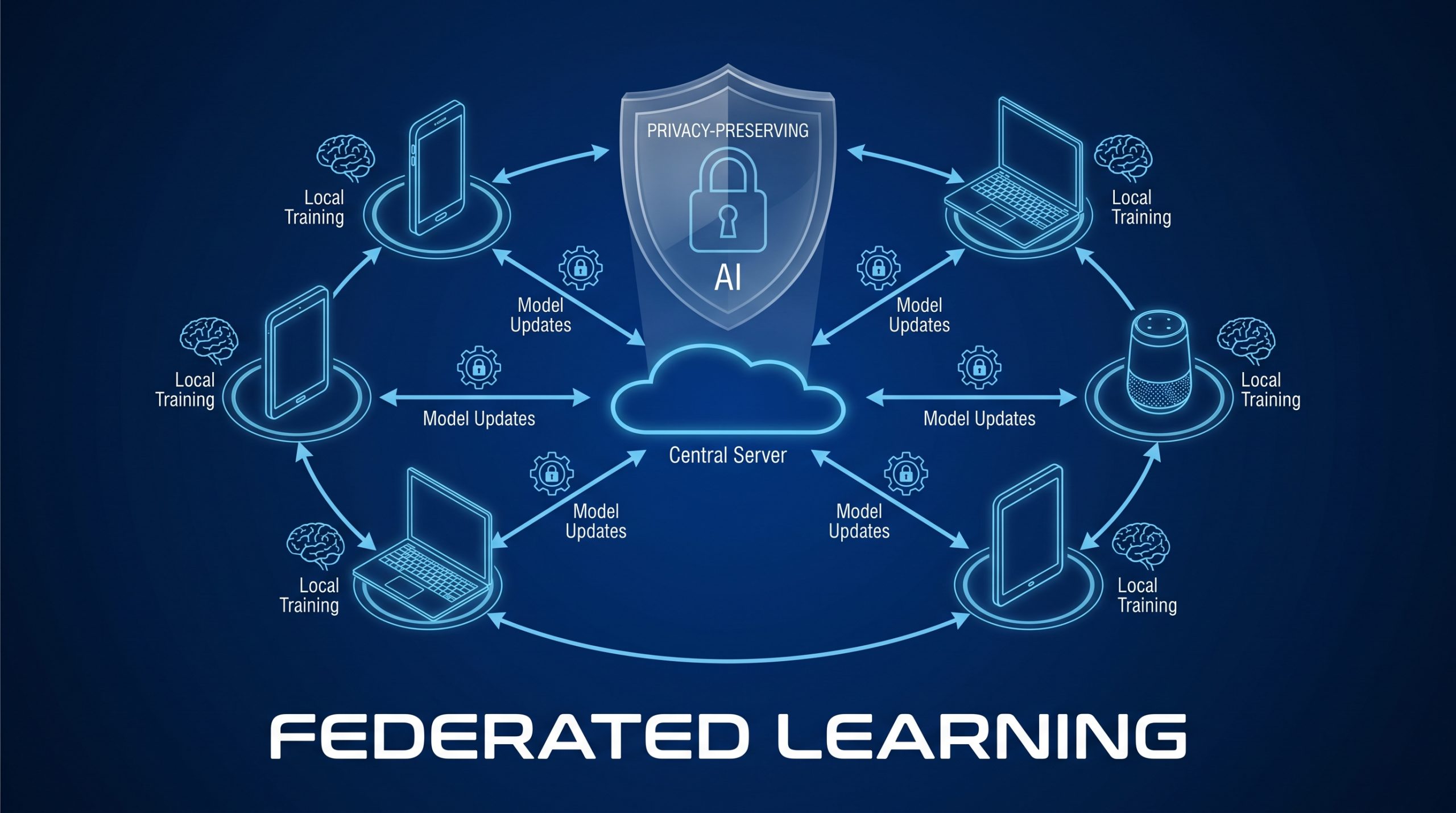
💡 Analogy: ลองจินตนาการว่าแต่ละโรงงานคือ “นักเรียน” ที่เรียนหนังสือจากหนังสือของตัวเอง (ข้อมูล) แล้วส่งเฉพาะ “สรุปความรู้” (Model Weights) ไปให้ครู (Central Server) รวมสรุปจากทุกคนเป็น “ความรู้ร่วม” — โดยไม่มีใครเห็นหนังสือของใคร
ทำไม Federated Learning ถึงสำคัญสำหรับอุตสาหกรรม?
1. ปกป้องข้อมูลลับทางการค้า
โรงงานผลิตชิ้นส่วนยานยนต์, อิเล็กทรอนิกส์, หรืออาหาร — ข้อมูลสูตรการผลิต, พารามิเตอร์เครื่องจักร, อัตราการผลิต ล้วนเป็นความลับทางการคารที่เสียหายได้หลายล้านบาทหากรั่วไหว FL ช่วยให้ฝึก AI โดย ข้อมูลดิบไม่เคยออกจากโรงงาน
2. ละเว้นข้อกังวลด้าน GDPR / PDPA
กฎหมายคุ้มครองข้อมูลส่วนบุคคล (GDPR ในยุโรป, PDPA ในไทย) จำกัดการส่งข้อมูลข้ามพรมแดน FL ช่วยให้ ข้อมูลยังอยู่ในประเทศ โดยส่งเฉพาะ Model Updates เท่านั้น
3. รวมความรู้จากหลายโรงงาน
บริษัทที่มีโรงงานหลายแห่ง หรือกลุ่มอุตสาหกรรมที่ต้องการร่วมมือกัน — สามารถฝึกโมเดล AI ร่วมกันได้ โดยข้อมูลของแต่ละโรงงาน ไม่ถูกแบ่งปันกัน
4. ใช้ประโยชน์จาก Edge Computing
FL ทำงานได้ดีบน Edge Device — สามารถฝึกโมเดลบน Edge GPU ที่วางอยู่ในโรงงานโดยตรง ลด Latency และลดความจำเป็นในการเชื่อมต่อ Internet ตลอดเวลา

ตารางเปรียบเทียบ: Centralized ML vs Federated Learning
| ประเภท | Centralized ML | Federated Learning |
|---|---|---|
| ตำแหน่งข้อมูล | รวมศูนย์ที่ Cloud | อยู่ที่แหล่งกำเนิด (On-premise) |
| ข้อมูลออกนอกโรงงาน? | ✅ ใช่ | ❌ ไม่ (ส่งเฉพาะ Model Weights) |
| ความเป็นส่วนตัว | ⚠️ ต่ำ | ✅ สูง |
| ความแม่นยำของโมเดล | สูงสุด (เห็นข้อมูลทั้งหมด) | สูง (ใกล้เคียง Centralized) |
| Network Bandwidth | สูง (ส่ง Raw Data) | ต่ำ (ส่ง Model Updates เท่านั้น) |
| GDPR/PDPA Compliance | ⚠️ ซับซ้อน | ✅ ง่ายกว่า |
| Communication Cost | สูง | ต่ำกว่า 10-100x |
Frameworks และ Tools สำหรับ Federated Learning
1. NVIDIA FLARE (Open Source)
พัฒนาโดย NVIDIA รองรับ Deep Learning Framework ทุกตัว (PyTorch, TensorFlow, scikit-learn) เหมาะสำหรับอุตสาหกรรมที่ใช้ NVIDIA GPU มี Privacy Filter ป้องกัน Data Leakage จาก Model Gradients
2. PySyft (OpenMined)
Open-Source Framework สำหรับ Privacy-Preserving ML รองรับ Secure Multi-Party Computation (SMPC) และ Differential Privacy เป็นเลเยอร์เสริมความปลอดภัยให้ FL
3. TensorFlow Federated (TFF)
พัฒนาโดย Google ผสานรวมกับ TensorFlow ได้ดี เหมาะสำหรับ Research และ Prototyping แต่ยังไม่เหมาะกับ Production ขนาดใหญ่
4. Flower (Adap)
Framework ที่ยืดหยุ่นที่สุด รองรับ ทุก ML Framework (PyTorch, TensorFlow, scikit-learn, XGBoost) และรองรับทั้ง Simulation และ Real Deployment มี Community ใหญ่ที่สุดในปัจจุบัน
Use Case ในอุตสาหกรรม
Case 1: Predictive Maintenance ข้ามโรงงาน
บริษัทที่มีโรงงาน 5 แห่ง แต่ละแห่งมีเครื่องจักรเหมือนกัน — ฝึกโมเดล PM ร่วมกันด้วย FL ทำให้โรงงานที่มีข้อมูลน้อย (เพิ่งเปิดใหม่) ได้ประโยชน์จากข้อมูลของโรงงานอื่น โดย ไม่ต้องแชร์ข้อมูลการผลิต
Case 2: Quality Control ร่วมกันในกลุ่มอุตสาหกรรม
กลุ่มโรงงานอิเล็กทรอนิกส์หลายแห่ง ฝึกโมเดล Defect Detection ร่วมกัน — แต่ละโรงงานมี Defect Type ที่แตกต่างกัน การรวม Model Updates ทำให้โมเดล “รู้จัก” Defect หลากหลายมากขึ้น
Case 3: Supply Chain Collaboration
Supplier และ Manufacturer ร่วมกันฝึกโมเดล Demand Forecasting โดย FL — โดย Supplier ไม่เห็นข้อมูลคำสั่งซื้อของ Manufacturer และ Manufacturer ไม่เห็นข้อมูลต้นทุนของ Supplier
ความท้าทายและข้อจำกัด
- Communication Overhead: แต่ละรอบ Training ต้องส่ง Model Updates ไป-กลับ อาจใช้เวลานานกว่า Centralized 2-5x
- Non-IID Data: ข้อมูลของแต่ละโรงงานอาจแตกต่างกันมาก (คนละผลิตภัณฑ์, คนละเครื่องจักร) ทำให้ Model Convergence ช้าลง
- Heterogeneous Hardware: แต่ละโรงงานอาจใช้ GPU ต่างรุ่นกัน — ต้องใช้ Async FL Algorithm
- Byzantine Robustness: โรงงานบางแห่งอาจส่ง Model Updates ที่ “ผิดพลาด” (จงใจหรือไม่จงใจ) — ต้องมี Aggregation Algorithm ที่ทนทานต่อ Outlier
🔧 Best Practice: เพิ่ม Differential Privacy (DP) เป็นเลเยอร์เสริม — เติม Noise เล็กน้อยให้ Model Weights ก่อนส่งออก ป้องกันการ “สืบค้นย้อน” (Reverse Engineering) ข้อมูลดิบจาก Model Updates ได้
Key Takeaways
- ✅ Federated Learning ฝึก AI โดยข้อมูลไม่ออกจากโรงงาน — ส่งเฉพาะ Model Weights/Gradients เท่านั้น
- ✅ เหมาะสำหรับอุตสาหกรรม ที่มีข้อกังวลด้านความลับทางการค้า, GDPR/PDPA Compliance
- ✅ Flower Framework เป็นตัวเลือกยอดนิยม — ยืดหยุ่น, รองรับทุก ML Framework, Community ใหญ่
- ✅ ใช้ร่วมกับ Differential Privacy เพื่อเพิ่มความปลอดภัยอีกชั้น
- ✅ Use Case หลัก: Predictive Maintenance ข้ามโรงงาน, Quality Control ร่วม, Demand Forecasting
- ✅ ข้อจำกัด: Communication Overhead สูงกว่า, Convergence ช้ากว่า Centralized ML แต่ Privacy ดีกว่าอย่างมหาศาล