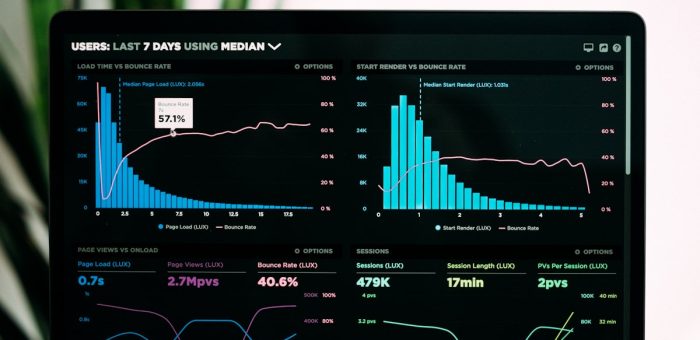
Time-Series Foundation Models: รุ่นใหม่ของ AI พยากรณ์อนุกรมเวลาที่ไม่ต้อง Train ใหม่ทุกครั้ง
ในโลกของ AI เปลี่ยนไปอย่างสิ้นเชิงเมื่อ Large Language Models อย่าง GPT เริ่มนำแนวคิด "Foundation Model" มาสู่ข้อมูลอนุกรมเวลา (Time-Series Data) ที่เป็นหัวใจของอุตสาหกรรม ตอนนี้ Time-Series Foundation Models กำลังปฏิวัติการพยากรณ์ในโรงงานอัจฉริยะ โดยไม่ต้อง Train โมเดลใหม่ทุกครั้ง Time-Series Foundation Models คืออะไร? Time-Series Foundation Models (TSFM) เป็นโมเดล AI ขนาดใหญ่ที่ถูก Pre-Train บนข้อมูลอนุกรมเวลาหลายพันล้านจุด (Billions of Time-Series Data Points) จากหลากหลายโดเมน เช่น การเงิน สภาพอากาศ การใช้พลังงาน การจราจร และอุตสาหกรรม แตกต่างจากโมเดลพยากรณ์แบบดั้งเดิมที่ต้อง Train เฉพาะสำหรับแต่ละงาน TSFM สามารถ Zero-Shot Forecasting ได้ทันทีบนข้อมูลใหม่ที่ไม่เคยเห็นมาก่อน 🚀 จุดเปลี่ยน: TSFM ทำให้การสร้างโมเดลพยากรณ์ที่เคยใช้เวลาหลายสัปดาห์ ลดลงเหลือเพียง ไม่กี่นาที เพราะสามารถพยากรณ์ได้ทันทีโดยไม่ต้องฝึกใหม่ (Zero-Shot) หรือฝึกเสริมเพียงเล็กน้อย (Few-Shot Fine-Tuning) ปัญหาของ Time-Series ML แบบดั้งเดิม ในโรงงานอุตสาหกรรม การสร้างโมเดลพยากรณ์อนุกรมเวลาแบบดั้งเดิม เช่น ARIMA, LSTM, หรือ Prophet มักประสบปัญหา: ต้อง Train ใหม่ทุก Task: ทุกเครื่องจักร ทุกสายการผลิต ทุกตัวแปร ต้องสร้างโมเดลแยกกัน ไม่มีการแบ่งปันความรู้ ต้องการข้อมูลประวัติยาวนาน: โมเดลส่วนใหญ่ต้องการข้อมูลอย่างน้อย 3-12 เดือนจึงจะพยากรณ์ได้แม่นยำ ไม่สามารถ Generalize: โมเดลที่ Train สำหรับเครื่องจักร A ไม่สามารถนำไปใช้กับเครื่องจักร B ได้ Cold Start Problem: เครื่องจักรใหม่ที่เพิ่งติดตั้งเซ็นเซอร์ไม่มีข้อมูลเพียงพอให้ Train โมเดล Multivariate Complexity: การพยากรณ์หลายตัวแปรพร้อมกันต้องการสถาปัตยกรรมซับซ้อนและเวลาฝึกนาน สถาปัตยกรรมหลักของ TSFM TSFM ส่วนใหญ่ดัดแปลงสถาปัตยกรรมจาก NLP มาใช้กับ Time-Series: 1. Tokenization สำหรับ Time-Series ข้อมูลอนุกรมเวลาถูกแปลงเป็น Token โดยแบ่งเป็นช่วง (Patch) แต่ละช่วงประกอบด้วย 8-64 จุดข้อมูล จากนั้นจึงส่งเข้า Transformer…