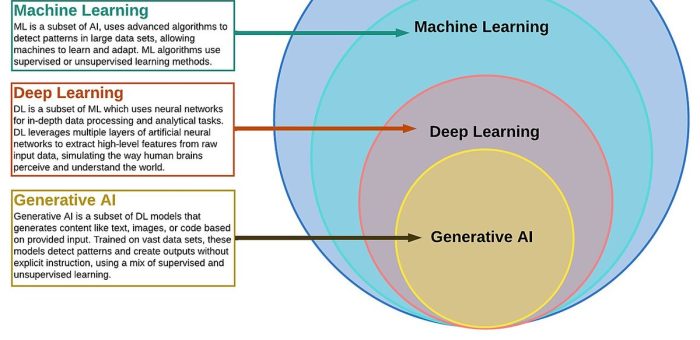
Self-Supervised Learning สำหรับ Industrial AI: เรียนรู้จากข้อมูลไร้ป้ายในโรงงาน
โรงงานอุตสาหกรรมทุกแห่งผลิตข้อมูลมหาศาลทุกวินาที — เซ็นเซอร์สั่นสะเทือน กล้องตรวจสอบคุณภาพ เครื่องวัดอุณหภูมิและแรงดัน — แต่ข้อมูลเหล่านี้ กว่า 95% เป็นข้อมูลปกติที่ไม่มีป้ายกำกับ (unlabeled data) การจะนำข้อมูลเหล่านี้ไปฝึกโมเดลตรวจจับตำหนิแบบมีผู้สอน (supervised) ต้องเสียเวลาและบุคลากรผู้เชี่ยวชาญในการระบุตำหนิทีละภาพ ซึ่งช้าและมีค่าใช้จ่ายสูง Self-Supervised Learning (SSL) คือวิธีที่ทำให้ AI เรียนรู้รูปแบบที่ซ่อนอยู่จากข้อมูลไร้ป้ายเหล่านี้ได้ด้วยตัวมันเอง Self-Supervised Learning คืออะไร? SSL เป็นเทคนิคที่สร้าง "สัญญาณการเรียนรู้" ขึ้นมาจากโครงสร้างของข้อมูลเอง โดยไม่ต้องมีมนุษย์มาติดป้ายกำกับ ระบบจะตั้ง ภารกิจหลอก (pretext task) ให้โมเดลทำนายส่วนหนึ่งของข้อมูลจากส่วนอื่น เช่น ทายทิศทางการหมุนของภาพ หรือเติมส่วนที่ถูกปิดไว้ (masked) จากการทำภารกิจเหล่านี้ โมเดลเรียนรู้ การแทนคุณลักษณะ (representation) ที่สามารถนำไปใช้ต่อกับงานจริงได้ โดยใช้ข้อมูลที่มีป้ายนิดเดียวในขั้นปรับแต่งสุดท้าย (fine-tuning) 🧠 เหตุผลสำคัญ: ผลงานวิจัยพบว่าโมเดลที่ผ่านการฝึกแบบ self-supervised สามารถบรรลุประสิทธิภาพใกล้เคียงหรือบางครั้งสูงกว่า supervised learning ในงานตรวจจับความผิดปกติ ในขณะที่ใช้ข้อมูลที่มีป้ายน้อยลงมาก วิธีการหลักของ SSL ในงานอุตสาหกรรม Contrastive Learning: สอนโมเดจับคู่ข้อมูลที่ "คล้ายกัน" (เช่น ภาพผลิตภัณฑ์ปกติสองมุม) ให้อยู่ใกล้กันในเวกเตอร์สเปซ และดันข้อมูลที่ "ต่างกัน" ให้ออกห่าง เป็นวิธียอดนิยมในการสร้างโมเดลพื้นฐานที่แยกแยะตำหนิได้ Masked Modeling: ปิดบางส่วนของสัญญาณเซ็นเซอร์หรือภาพแล้วให้โมเดลเติมให้ถูกต้อง เหมาะกับข้อมูลอนุกรมเวลา (time-series) จากเครื่องจักร Synthetic Anomaly: ฉีดตำหนิสังเคราะห์ลงในภาพปกติเพื่อสร้างข้อมูลฝึก เนื่องจากตำหนิจริงในโรงงานมีน้อยมาก เทคนิคนี้ช่วยให้ตรวจจับตำหนิได้โดยไม่ต้องรอสะสมตัวอย่างตำหนิจริง Predictive / Reconstruction: ให้โมเดลเรียนรู้สร้างภาพซ้ำจากข้อมูลปกติ เมื่อเจอข้อมูลผิดปกติโมเดลจะ "สร้างได้ไม่ดี" ส่งสัญญาณว่าพบความผิดปกติ เปรียบเทียบกระบวนทัศน์การเรียนรู้ มิติเปรียบเทียบ Supervised Unsupervised Self-Supervised ต้องมีป้ายกำกับ? ✅ มาก ❌ ไม่มี ป้ายน้อย (final step) ใช้ประโยชน์จากข้อมูลไร้ป้าย ❌ ✅ ✅ ดีมาก ตรวจจับตำหนิประเภทใหม่ ❌ (ต้องเคยเห็น) ปานกลาง ✅ ได้ดี คุณภาพ representation ดี (งานเฉพาะ) ต่ำ-ปานกลาง ✅ ดีมาก ภาระการติดป้ายมนุษย์ สูงมาก ไม่มี ต่ำ กรณีประยุกต์ใช้ในโรงงาน ตรวจจับตำหนิที่ไม่เคยพบ (Novel Anomaly Detection): โมเดลที่เรียนรู้แต่ "ความปกติ" จากภาพผลิตภัณฑ์ดีหลายหมื่นภาพ…