Data Lake สำหรับโรงงานอุตสาหกรรม: จาก Data Silo สู่ Data-Driven Factory
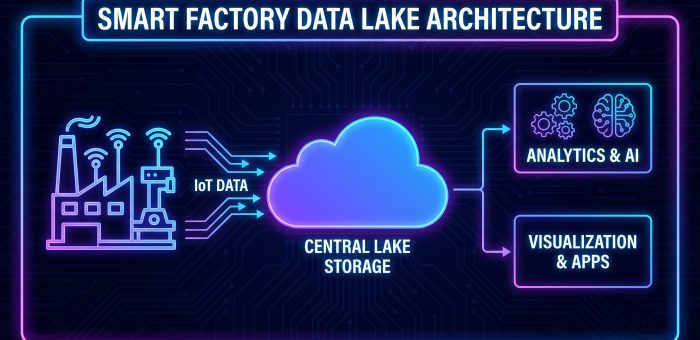
Data Lake สำหรับโรงงานอุตสาหกรรม: จาก Data Silo สู่ Data-Driven Factory ในโรงงานอุตสาหกรรมยุคใหม่ ข้อมูลถูกสร้างขึ้นจากหลากหลายแหล่ง — SCADA, PLC, Sensor IoT, MES, ERP, LIMS (Laboratory Information Management System) และอีกมากมาย ปัญหาคือข้อมูลเหล่านี้มักกระจัดกระจายอยู่ใน “Data Silo” แยกกัน ทำให้วิเคราะห์ข้ามระบบไม่ได้ Data Lake เป็นแนวทางสถาปัตยกรรมที่แก้ปัญหานี้โดยรวบรวมข้อมูลทุกประเภทไว้ในที่เดียว ทั้ง Structured, Semi-structured และ Unstructured ต่างจาก Data Warehouse ที่ต้องกำหนด Schema ล่วงหน้า (Schema-on-Write) Data Lake ใช้หลักการ Schema-on-Read คือเก็บข้อมูลดิบ (Raw Data) ก่อน แล้วค่อยกำหนดโครงสร้างตอนอ่านมาวิเคราะห์ ทำให้รองรับข้อมูลได้หลากหลายกว่าและเพิ่ม Source ใหม่ได้ง่ายกว่า สถาปัตยกรรม Data Lake สำหรับโรงงาน (Industrial Data Lake) Industrial Data Lake มีโครงสร้าง 4 ชั้นหลัก: Ingestion Layer: รับข้อมูลจากทุกแหล่ง — MQTT Broker (Sensor Data), OPC UA (PLC/SCADA), Database Connector (ERP/MES), File Upload (CAD, Report PDF) รองรับทั้ง Batch และ Real-time Streaming Storage Layer: เก็บข้อมูลใน Object Storage หรือ Hadoop Distributed File System (HDFS) แบ่งเป็น 3 Zone: Raw Zone (Bronze), Cleansed Zone (Silver), Curated Zone (Gold) Processing Layer: ใช้ Apache Spark หรือ Apache Flink ประมวลผลข้อมูลทั้ง Batch และ Stream ทำ ETL/ELT,…

