Time Series Forecasting ด้วย Deep Learning ในโรงงาน: จาก LSTM ถึง Transformer สำหรับพยากรณ์ Process แบบ Multivariate
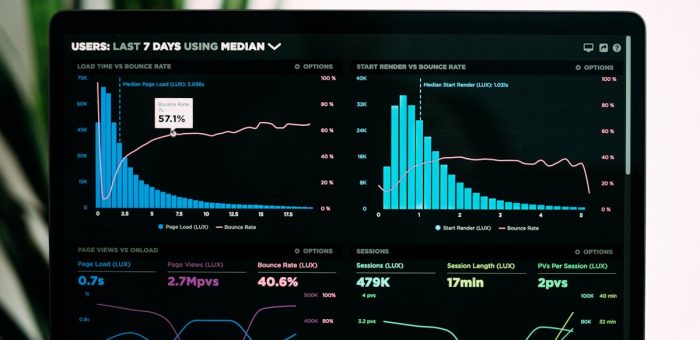
การพยากรณ์ (forecasting) คือหัวใจของการตัดสินใจในโรงงานอัจฉริยะ — พยากรณ์ความต้องการพลังงาน พยากรณ์ yield ของสายผลิต พยากรณ์อายุการใช้งานเครื่องจักร พยากรณ์ quality drift ทุกการพยากรณ์ที่แม่นยำขึ้น 10% สามารถลดต้นทุนการผลิตได้อย่างมีนัยสำคัญ ในอดีตการพยากรณ์อาศัย statistical model เช่น ARIMA หรือ Exponential Smoothing ซึ่งจำกัดที่ univariate และเส้นตรง แต่ในยุค Deep Learning LSTM, Transformer และ Temporal Fusion Transformer กำลังเปลี่ยนวิธีที่โรงงานพยากรณ์ทุกอย่าง ข้อจำกัดของ Traditional Forecasting โมเดลสถิติแบบดั้งเดิมมีข้อจำกัดที่สำคัญในบริบทอุตสาหกรรม: ARIMA/SARIMA — ทำงานได้ดีกับ univariate time series ที่ stationary แต่โรงงานจริงมี ตัวแปรภายนอก (อุณหภูมิ, ความดัน, production rate) ที่ส่งผลต่อค่าที่พยากรณ์ เส้นตรงเป็นหลัก — ความสัมพันธ์ในกระบวนการผลิตมักเป็น non-linear ที่ statistical model จับไม่ได้ Manual feature engineering — ต้องกำหนด seasonality, trend, lag manually ทำได้ยากเมื่อมีรอบการผลิตซับซ้อน Point forecast เท่านั้น — ให้ค่าเดียว ไม่บอกความไม่แน่นอน ทำให้ตัดสินใจเสี่ยง Deep Learning Models สำหรับ Time Series 1. LSTM (Long Short-Term Memory) LSTM เป็น Recurrent Neural Network ที่ออกแบบให้จำ pattern ระยะยาวได้ ผ่านกลไก forget gate, input gate, output gate ที่ควบคุมว่าข้อมูลไหนควรเก็บ ลืม หรือส่งต่อ LSTM เหมาะกับ: Time series ที่มี dependency ระยะไกล (long-range dependency) Multivariate forecasting — รับ input หลายตัวแปรพร้อมกัน Sequence-to-sequence task เช่น พยากรณ์ 24 ชั่วโมงข้างหน้าจากข้อมูล…